


一文搞定 Firecrawl,让你的 AI 项目省掉抓取环节的所有痛点
想在 RAG、聊天机器人或数据分析里用网页内容,却总被乱七八糟的 HTML、JS 渲染和验证码卡住?这篇文章教你用 Firecrawl 把网站“一键转成干净的 Markdown / JSON”,省时省力又省钱。
很多人以为自己必须写爬虫脚本、配代理、处理验证码,甚至得自己跑 Playwright,才算“真正抓到数据”。
实际情况是:Firecrawl 已经把这些底层细活封装成一个 API,直接返回 LLM 友好的结构化数据,几分钟就能上手。

Firecrawl 的核心本质(First Principles)
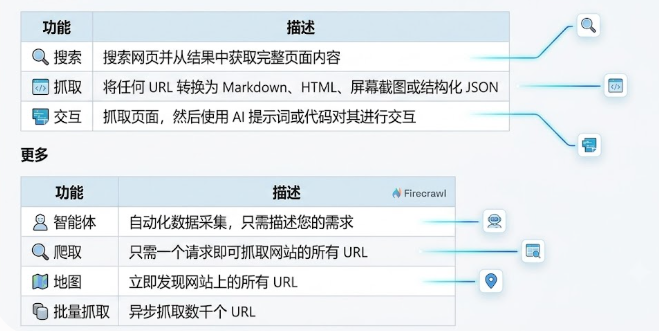
- API‑first、无状态:只要一个 API Key,任何语言都能调起抓取、爬取、映射、搜索、交互等功能。
- 自动渲染 + 反爬处理:内部维护一套浏览器池,能运行 JavaScript、处理 Cloudflare、验证码等。
- LLM‑ready 输出:默认返回 Markdown,附带结构化 JSON,省去后处理的步骤。
- 统一计费模型:每次抓取消耗 1 Credit,额度透明,适合按量付费。
实战经验分享:我用了 Firecrawl 搞了哪些项目
以下是我这几年在实际项目里踩过的几种典型场景,帮助你快速定位自己的需求。
- 构建“与网站聊天”机器人:把目标站点的所有子页面(约 200 页)交给
crawl接口,一键得到全站 Markdown,直接喂进 LangChain 的向量库,用户提问时几乎零延迟。 - 从招聘平台抽取结构化职位信息:使用
scrape+extract(JSON 模式)配合自定义 Pydantic Schema,只需一行代码就返回{title, location, salary, skills},省掉手写正则的苦恼。 - SEO 竞争分析:先用
map把竞争对手的所有文章链接列出来,再批量scrape成 Markdown,配合agent自动生成竞争报告。
以上项目中,我最常遇到的问题是「网站会因频繁请求被封」,但只要把 API Key 的配额提升到合适的层级,或者在 crawl 时调小 limit,配合 poll_interval,几乎不再出现被拦。
Firecrawl 与同类工具对比(以 Crawl4AI 为例)
| 特性 | Firecrawl | Crawl4AI |
|---|---|---|
| 部署方式 | 托管 SaaS,免运维 | 本地部署,需要自行维护 Docker/Playwright |
| 语言支持 | REST + Python/Node/Go/Java 等 SDK | 仅 Python |
| 动态渲染 | 内置浏览器池,自动处理 JS | 需自行配置 Playwright |
| 计费模型 | 信用制,100k 次约 $83 | 开源免费,实际成本在服务器+代理+LLM token |
| 搜索能力 | 单请求即可搜索 + 抓取 | 无内置搜索,需要自行集成 |
对大多数想快速落地的团队来说,Firecrawl 的“一站式”优势更明显;如果你已经有成熟的 Python 基础设施、对数据完全自行托管有强需求,那么 Crawl4AI 的开源自由度仍有价值。
如何一步完成 Firecrawl 接入
- 在 firecrawl.dev 注册账号,获取 API Key。
- 安装对应语言的 SDK(这里以 Python 为例):
pip install firecrawl-py - 调用最基础的
scrape示例:
from firecrawl import FirecrawlApp
app = FirecrawlApp(api_key="fc-你的_KEY")
result = app.scrape_url('https://example.com', params={'formats':['markdown']})
print(result['markdown'])
如果你需要抓取全站,只要把 crawl_url 的 limit 调大即可,返回的 id 用来轮询状态。
进阶技巧:结构化抽取与 Agent 自动化
- 使用 JSON 模式抽取:在
scrape的formats中加入{"type":"json","schema":YourSchema},直接得到结构化对象。 - Agent 端点:如果你甚至不知道要抓哪些页面,只要给一个自然语言 prompt,
/agent会自行搜索、导航、抽取,适合调研类任务。
想了解更细的 agent 用法,后面会详细拆解 prompt 编写技巧和 token 控制。
常见坑与规避方案
- **配额不足**:免费额度每月只有 500 Credit,使用前先在控制台查看用量,必要时升级计划。
- **页面渲染慢**:对极度复杂的单页应用,可以在
scrape参数里调高timeout,或者先用search确认 URL。 - **结构化抽取不准**:当 LLM 抽取出现误差时,尝试补充更明确的 JSON Schema 或者在
prompt中加入示例。
总结:Firecrawl 能帮你实现的价值
把“抓网页”这件事从「手写脚本」提升到「点按钮」的层级,让开发者可以把时间花在模型调参、业务逻辑和用户体验上。无论是做 RAG 知识库、构建聊天机器人,还是做 SEO 报告、价格监控,Firecrawl 都是值得先试的底层服务。
如果你已经在项目里用了类似的工具,或者想马上试一试 Firecrawl,欢迎在评论区聊聊你的使用感受或遇到的难点,大家一起碰撞出更好的解决方案 🚀。



评论 (0)