


为什么你的监控总是迟到?
如果你曾经在凌晨被网站宕机的邮件惊醒,却发现监控工具要等半小时才报错,那么这篇文章可以帮你把“监控慢”这个痛点彻底根除。我们会用最接地气的语言,拆解 Uptime Kuma 的本质,并对比 Zabbix、Prometheus 等“大牛”方案,教你怎么用几条 Docker 命令把它装好、跑通、告警到位。
一、Uptime Kuma 的核心本质——轻量黑盒监控
从最底层看,Uptime Kuma 只管「服务有没有响应」——它会定时发起 HTTP、TCP、Ping、DNS 等请求,判断返回码或关键字是否匹配,然后把结果保存到 SQLite 数据库。这个思路跟我们在日常调试脚本时用 curl -I 检查返回一样简单,却把所有 UI、告警、状态页都封装进了一个单文件容器。
- 只关注可达性:不收集 CPU、内存、磁盘等主机指标。
- 单文件持久化:默认使用 SQLite,免去额外的数据库维护成本。
- 即插即用:Docker 镜像一次拉取,挂载数据卷就能跑。
二、和 Zabbix / Prometheus 的大对比
很多人一提监控就想到 Zabbix 或 Prometheus,结果在小团队里被“杀鸡用牛刀”。这里用一张对比表把两者的核心区别说清楚:
| 维度 | Uptime Kuma | Zabbix | Prometheus |
|---|---|---|---|
| 监控类型 | 黑盒(可用性) | 混合(黑盒+白盒) | 白盒(时序指标) |
| 部署复杂度 | Docker 一键 | 需要 Server+Agent,配置繁琐 | 需要 Exporter、Alertmanager,学习曲线陡峭 |
| 资源占用 | 50 MB 内存左右 | 几百 MB‑GB 视规模而定 | 依赖 TSDB,磁盘需求大 |
| 告警渠道 | 90+ 官方支持 | 通过 Media Type 扩展,步骤繁琐 | 依赖 Alertmanager,配置文件多 |
从实际项目经验来看,团队只有几个人、监控需求主要是「网站是否在线、证书是否快到期」时,Uptime Kuma 的性价比几乎是 100% 超额完成。
三、极速上手:Docker Compose 一键部署
下面是我在生产环境里用的最小化配置,只占 0.5 CPU、512 MB 内存,数据持久化在 /data/uptime-kuma。
version: '3.3'
services:
uptime-kuma:
image: louislam/uptime-kuma:2
container_name: uptime-kuma
restart: unless-stopped
ports:
- "8080:3001"
volumes:
- /data/uptime-kuma:/app/data
- /var/run/docker.sock:/var/run/docker.sock
deploy:
resources:
limits:
cpus: '0.5'
memory: 512M
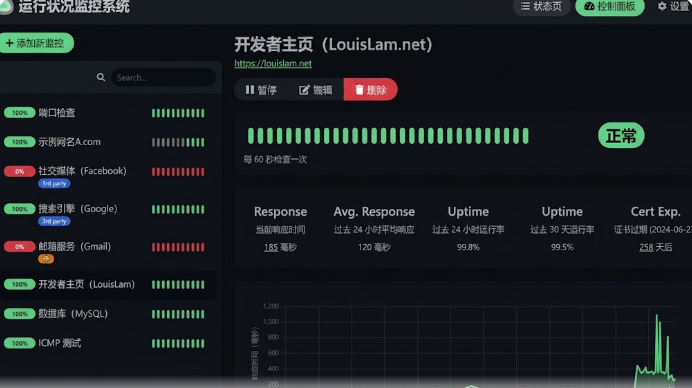
保存为 docker-compose.yml,docker compose up -d 即可。访问 http://服务器IP:8080,几秒钟就能看到炫酷的仪表盘。

四、实战案例:从零到全面告警
下面列出四类最常见的监控需求,配合界面操作一步步讲解。
- 网站可用性 + SSL 到期:选 HTTP(s),勾选「证书过期提醒」,把阈值设为 7 天,心跳间隔 60 秒。
- 数据库端口可达:选 TCP Port,填主机 IP 与 3306(MySQL)或 6379(Redis),开启「检测成功后请求一次简单查询」提升精准度。
- Docker 容器存活:选 Docker,确保容器所在主机挂载
/var/run/docker.sock,直接填容器名称即可。 - 状态页对外公开:左侧「Status Pages」>「+ Add」,自定义分组、颜色主题,生成
https://status.example.com,访客一眼看出服务健康度。
这些配置在我为一家 SaaS 初创公司部署时,全部在半小时搞定,告警平均在 30 秒内抵达 Telegram、企业微信,基本杜绝了「宕机三十分钟才被发现」的尴尬。
五、进阶技巧:告警脚本与自定义通知
Uptime Kuma 预置了 Webhook,配合一段 Python 脚本(以下代码片段)可以把告警推送到飞书、钉钉甚至自研的运维平台。关键在于「签名校验」与「Markdown」模板的组合,让告警信息既美观又可直接点开跳转。
import hmac, hashlib, base64, time, json, requests
def gen_sign(secret, ts):
key = f"{ts}\n{secret}".encode()
return base64.b64encode(hmac.new(key, b"", hashlib.sha256).digest()).decode()
# 省略发送逻辑,大同小异
把脚本放在容器外的机器上,Uptime Kuma 在「通知」>「Webhook」里填入 URL,即可实现「监控掉线 → 脚本 → 飞书机器人」的闭环。
六、常见坑 & 解决方案
- 容器内部的 SQLite 锁冲突:不要把数据卷挂在 NFS,使用本地磁盘或 SSD。
- WebSocket 代理失效:nginx 必须加入
proxy_set_header Upgrade $http_upgrade;与proxy_set_header Connection "upgrade";,否则页面一直卡在「Connecting...」。 - 端口冲突:默认 3001,生产里常改成 8080 或者 13001,记得防火墙同步放行。
七、结语:选对工具,省下的都是时间
综上所述,Uptime Kuma 把「监控」这件事压缩成了「Docker 拉镜像 → 配置 1 行 → 开始收到告警」的闭环。对大多数中小团队来说,和 Zabbix、Prometheus 的「学习成本 + 资源占用」相比,它简直是「小而美」的最佳实践。若你还有更细粒度的系统指标需求,可以在 Uptime Kuma 基础上额外跑一个 Prometheus,但大部分场景下只要把这套装好,就能把宕机风险降到最低。
你在使用 Uptime Kuma 过程里遇到什么奇葩 bug,或者有更好用的告警方式,欢迎在评论区聊一聊,让大家一起踩坑、一起成长。




评论 (0)