


打开语言的魔法盒:pyVideoTrans 轻松玩转视频翻译
有没有想过把一段外语短片变成自己懂的版本,而且还能听到配音?普通人往往觉得这事儿需要写代码、买昂贵的软硬件,甚至还得请专业译者。其实,一键打开 pyVideoTrans 这款开源工具,就能把“外语影片”瞬间变成“自家语言版”。下面,我像跟朋友聊咖啡一样,把它的使用全过程拆解开,让你能直接动手,而不必担心太难。
🛠️ 一句话概括:啥也不用写,一键搞定四大步骤
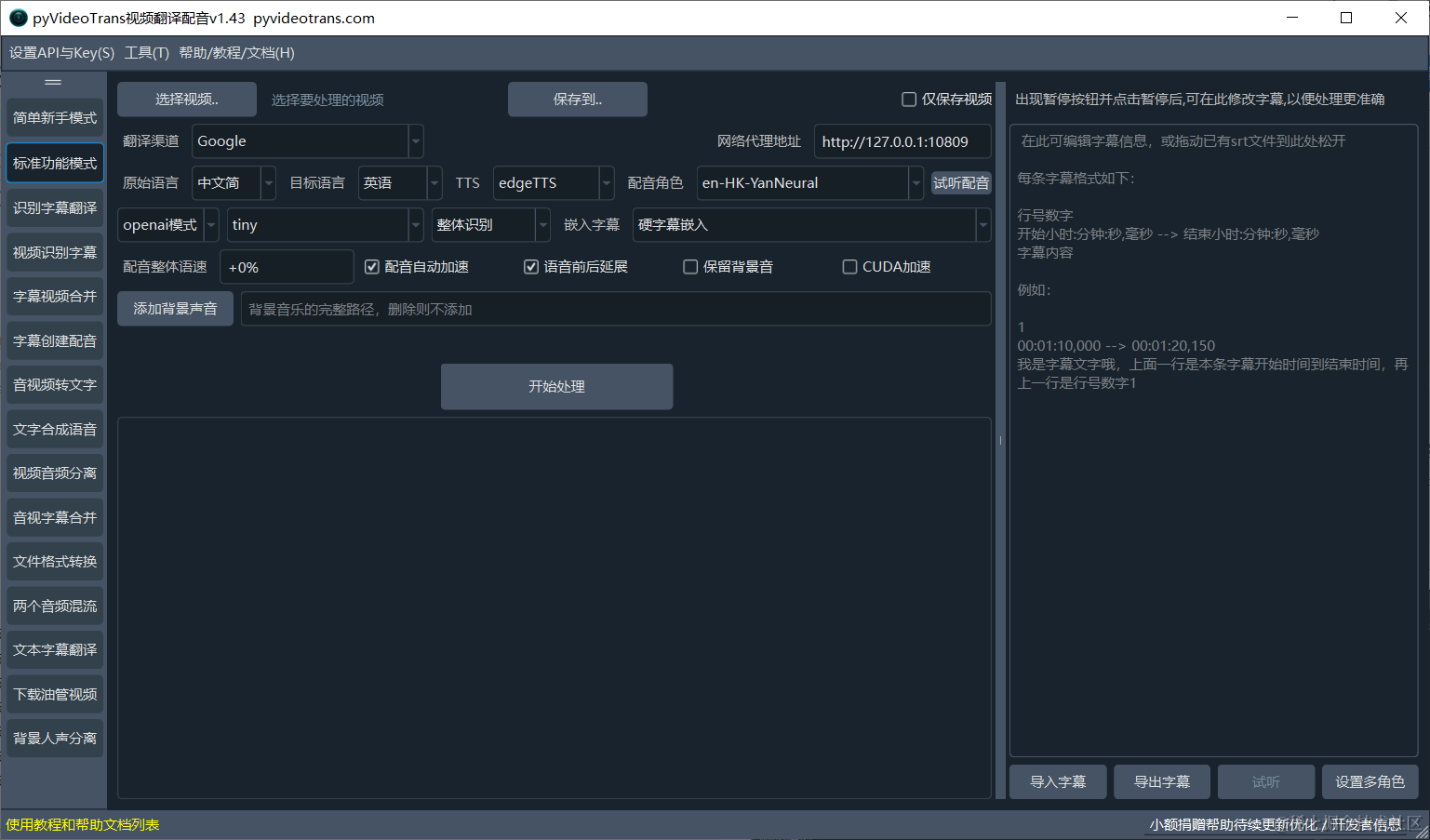
pyVideoTrans 把语音识别 → 字幕翻译 → AI 配音 → 视频合成四步打成一个链子。只要选对模型,点几下鼠标,就能得到一个带字幕、配音的新视频。
核心亮点(不看也行,先点开用)
- 本地离线模型 + 在线 API 任你挑,免费版 Edge‑TTS、Google 翻译、Faster‑Whisper 都开箱即用。
- 声音克隆功能:只要几秒的原声,生成的配音听起来像原主播在说别的语言。
- 多说话人识别(Speaker Diarization),每个人都能配不同的角色,避免“一锅粥式”配音。
- 可视化校对:每一步都可以暂停手动修改,确保字幕、翻译、配音不走偏。
- CLI(命令行)+ GUI 双模式,服务器上跑批处理,桌面上点点鼠标都行。
🚀 快速上手指南(不懂技术也能玩)
1️⃣ Windows 用户:开箱即用
- 去 GitHub Releases 页面下载最新的
win-pyvideotrans‑vX.xx.zip(约 3 GB)。 - 解压到
D:\pyVideoTrans(路径只能是英文、数字,别有空格或中文)。 - 双击
sp.exe,稍等几秒,软件会自行加载模型。
如果想要更快的识别速度,装好 CUDA 12.x + cuDNN 9.11,软件会自动使用 GPU。
2️⃣ macOS / Linux / 想自定义的朋友:源码部署
- 确保系统安装
Python 3.10‑3.12、FFmpeg(brew install ffmpeg/apt‑get install ffmpeg)。 - 推荐使用
uv包管理器:curl -LsSf | sh(macOS/Linux)powershell -c "irm https://... | iex"(Windows) - 克隆仓库并同步依赖:
git clone https://github.com/jianchang512/pyvideotrans.gitcd pyvideotransuv sync - 运行 GUI:
uv run sp.py,或者用 CLI:uv run cli.py --help
🔧 关键配置:选对模型,效果翻倍
下面列出常见的组合,帮你省心挑选:
| 功能 | 推荐本地模型 | 在线 API(免费/付费) |
|---|---|---|
| 语音识别 (ASR) | Faster‑Whisper large‑v3(中文/英文都行) | OpenAI Whisper、Alibaba Qwen‑ASR |
| 字幕翻译 | 本地 Ollama(M2M100) | DeepSeek、ChatGPT、Google 翻译 |
| 配音 (TTS) | 本地 F5‑TTS / CosyVoice(支持声音克隆) | Edge‑TTS(免费)、OpenAI TTS、Elevenlabs |
如果你手头没有 GPU,先走本地模型;有显卡的话,记得勾选 CUDA 加速,识别和配音速度能提升数十倍。
📹 实际操作演练(以一部 5 分钟的英文纪录片为例)
- 选文件:左侧工具栏点 "自定义配置翻译" → "选择视频",把
documentary.mp4加进来。 - 语言设置:原语选择 "English",目标语言选择 "Chinese (Simplified)"。
- 识别渠道:选 "Faster‑Whisper large‑v3",打开 "二次识别"(配音后再校对字幕)。
- 翻译渠道:直接选 "Free Google"(不需要代理),如果想要更自然的表达,改用 "DeepSeek" 并填入 API Key。
- 配音渠道:默认 "Edge‑TTS",挑一个中文男声角色 "zh-CN-YunyangNeural"。若想要「原声克隆」,把配音角色改成 "clone",并在弹窗里上传 3‑5 秒原声样本。
- 高级选项:
- 开启 "识别说话人",设定 2 位说话人。
- 配音语速调至 +10%(让配音稍快,防止太慢拖片子)。
- 勾选 "音频加速",自动让配音时长贴合原始时长。
- 点开始:软件会依次弹出字幕编辑、翻译校对、配音角色分配界面,随意点 "确定" 或手动微调。
- 完成:进度条走到尽头后,点击打开输出文件夹,里边会有
documentary_translated.mp4、subtitle_zh.srt、dub_zh.wav等。
打开新视频,你会看到画面里原来的英文字幕已经被中文软字幕覆盖,配音也换成了中文声音,几乎没有延迟。
💡 小技巧与坑点(避免踩雷)
- 文件名要简短:Windows 对路径长度有限制,长文件名容易报错。建议文件名不超过 30 字符。
- 避免特殊字符:"?", "*", ":" 等符号会导致软件读取失败。
- 先跑小样本:第一次使用本地模型会自动下载数 GB 的权重,建议先用几秒的短片验证配置。
- 配音时长不匹配:如果配音后仍然比原视频长,打开 "同步对齐",选择 "视频慢速" 或 "音频加速"。
- 说话人识别不准:可以在 "高级选项"里预设说话人数,或者手动在字幕编辑窗口把错误的说话人标签改正。
- 网络代理:使用 Google、OpenAI 等国外服务时,需要在「网络代理」里填上你的 VPN 端口(如
socks5://127.0.0.1:1080)。
🧩 扩展玩法(不止翻译)
pyVideoTrans 的工具箱里还有不少隐藏功能,像是:
- 把音频和视频分离,给配音加背景音乐。
- 把已有的 SRT 字幕批量翻译成多语言双字幕。
- 使用 CLI 实现服务器上 24 小时自动转译工作流(适合自媒体运营)。
- 利用 "声纹克隆" 把博主的声音变成多个语言的配音,保持个人品牌音色。
💬 结语:从技术小白到视频翻译达人只差一个工具
看完这篇,仿佛已经在脑子里玩转了整个流程。pyVideoTrans 把原本碎片化的 AI 能力(ASR、MT、TTS)打包成一键操作,让普通人也能把外语内容变成本地语言的视听作品。不需要写代码、也不必花钱买专业翻译软件,只要跟着上面的步骤走,几分钟就能拥有自己的多语言视频。
如果你经常需要处理跨语言的短片、课程或访谈,赶紧下载试用吧,用完以后别忘了在 GitHub 给大家点星星,帮助项目维持开源活力。
祝大家玩得开心,翻译顺利 🎉!
评论 (0)